「元気なごみ」使用 jenkins 每日自动将卡片 state 文件备份到 github
写到最前:请注意网络安全问题
文章是假定,所有服务处于一个相对封闭和独立的网络。所以对于权限控制等方面的考量,偏简化风格。如果您正在为一个真正对外使用的服务进行配置,请务必好好斟酌,尽可能缩小不同用户的权限,同时尽可能谨慎地放开网络方面的访问限制。
背景
基于文章标题,显而易见,这是一个我在零碎时间完成的事。
问题的起因是:我自制的间隔复习的闪卡系统,目前核心数据是存储到我的家庭网络内的。随着闪卡系统在我的各种生活和学习中,发挥着越来越重要的作用,对闪卡核心记录数据的丢失的担忧,也越来越多。
我过去几周的临时方案是:把闪卡数据文件导出,然后手动上传到 github 备份。但是,这有些繁琐,而且真正忙时,大概率是顾不上做了。
重要的事,要提前做。真正重要的事,要 自动 做。再重要的事,只要把成本,压缩到趋近于零,才有可能长久坚持。
思路概述
graph TD
A[Jenkins Job 每日执行特定脚本]
--> A0[脚本内:获取卡片最新状态文件]
--> A1[脚本内:状态文件写入本地Git目录]
--> A2[脚本内:本地Git目录提交到 Github]
--> A3[脚本内:发送邮件,告知执行结果]
--> A4[我:每天看下邮件汇总]
Jenkins Job 每日执行特定脚本
- Job 的每日执行,是基于 Jenkins job 配置的 Build Triggers 中的 Build periodically
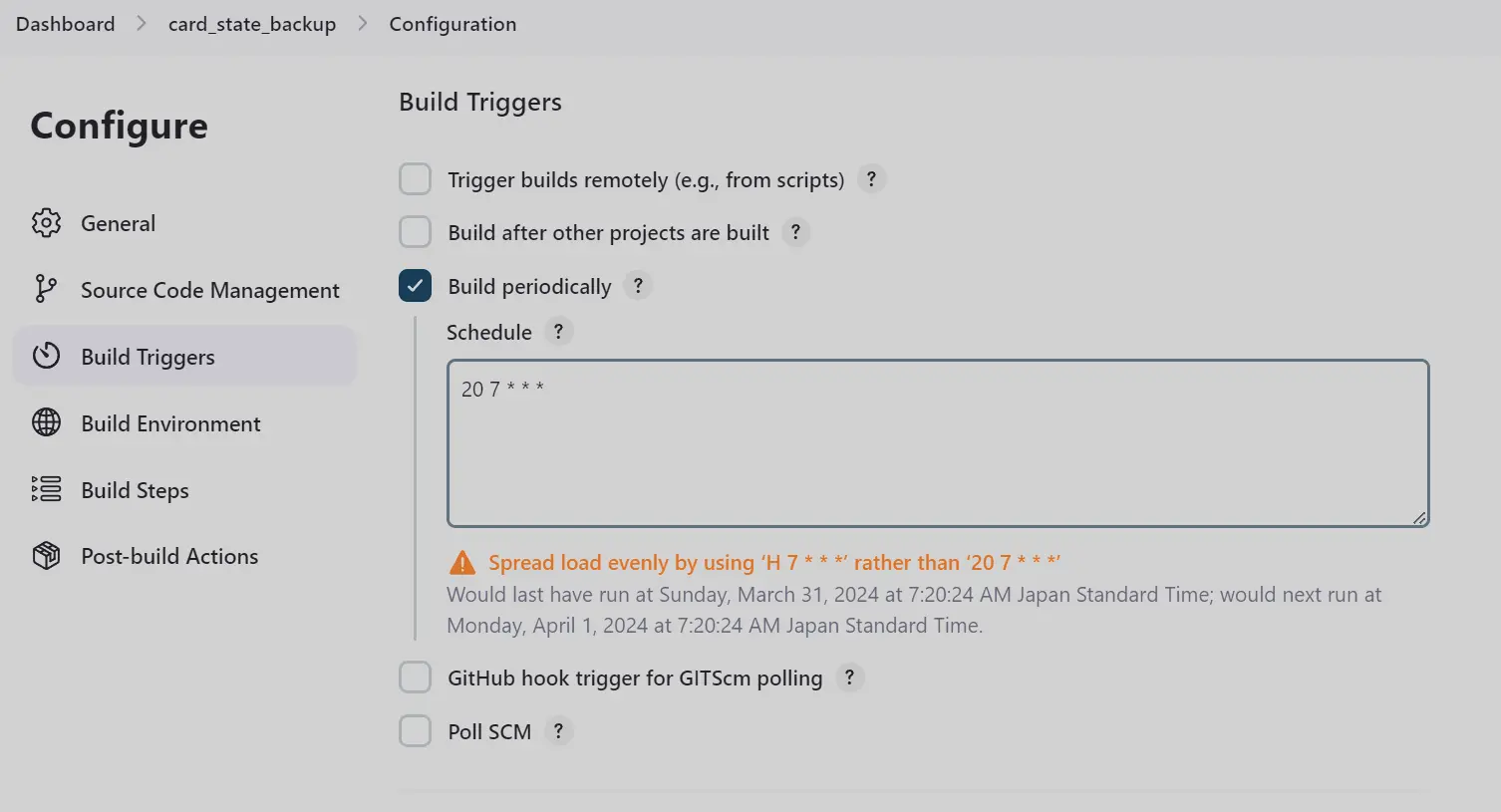
-
我的卡片系统目前 Jenkins 目前没有在一个系统上。所以,我需要给卡片系统配置一个 Jenkins Agent。逻辑听起来有点奇怪。这个要自己去权衡下。因为我预期的效果是:在机器A上调完 python 脚本后,直接在 Jenkins job 中调用这个脚本。所以为了尽可能保持一致,我需要保证 Jenkins job 以一种几乎完全一致的方式来调用我在特定机器上写的脚本。所以,最稳妥的方式就是在该机器上直接配置一个 jenkins agent。
-
jenkins agent,这次我没有基于 docker 来部署,后续也会尽量剥离 docker。我发现在家庭开发环境中,docker给我带来了不必要的心智负担和配置管理负担。家用环境,稳定性是次要的,高速开发和验证,尽可能简化和一致的配置体验,才是核心。我这次尝试配置 job 时,发现 python 文件的调用总是提示找不到文件,后来才发现,我最初的 python 目录时 mount 到 jenkins 本身所在的 docker contaienr的。虽然,最后还是定位到了问题,但是后续我不想再被类似的问题困扰。至于目前已知的 docker 的对于我的好处,并没有实际的不可替代的地方,甚至系统native的解决方案,更灵活和易于管理。目前已知的一个不可替代的场景就是:偶尔要跑一个特殊的系统,这个系统与我的Linux系统有无法调和的冲突。我不确定会不会真的遇到类似的问题。如果真遇到了,我可能会选择直接配置一个虚拟机专门安装对应的系统吧。反正家用环境下,各种资源要远比各种云服务廉价的。
-
经过简单的调研后,我这次是用系统默认的 Service 管理服务 systemd 来实现 jenkin agent 的自动启动的。为了实现最初的 脚本的本地运行 与 jenkins job 调用运行,两者尽可能一致的预期结果,我这次是用同一个 linux 账户来配置 service,而不是大多数教程中推荐的另外配置一个专门的 jenkins账户。这有一些细微而重要的差异,比如 jenkins 账户可能没有本地 github git 库的实际访问权限,进而无法实际往远端 push 代码。
-
我分享下我的 run_jenkins_agent.service 文件。其中涉及路径的部分,请自行根据情况修改下。
[Unit]
Description=Jenkins Agent
[Service]
User=kyo
WorkingDirectory=/home/kyo/jenkins_agent
ExecStart=/bin/bash /home/kyo/github/linux_systemd_service/run_jenkins_agent.sh
Restart=always
[Install]
WantedBy=multi-user.target
- run_jenkins_agent.sh 文件如下。主要代码在新建 jenkins agent 后,最后出现的配置界面能看到。
#!/bin/bash
cd /home/kyo/jenkins_agent
# Just in case we would have upgraded the controller, we need to make sure that the agent is using the latest version of the agent.jar
curl -sO http://jenkins.yanfeng.life/jnlpJars/agent.jar
java -jar /home/kyo/jenkins_agent/agent.jar -jnlpUrl http://jenkins.yanfeng.life/computer/devhome/jenkins-agent.jnlp -secret @/home/kyo/jenkins_agent/secret-file -workDir "/home/kyo/jenkins_agent"
exit 0
- 在分享几个我梳理的常用命令的例子。我的记忆力也很普通,所以我喜欢把常用的相关的东西记到一块,保证我下次用时,能随手就拿到。像我这种记忆力一般,又有点懒的人,对脑力成本非常敏感。如果一件事处理方式,不符合我的大脑的直觉,如果有的选,我大概率会选一种更符合我大脑直接的方式,比如这次初步决定尽快脱离 docker;如果没的选,我大概率会写一些文档来记录下,避免二次踩坑,或者至少保证下次能尽快地恢复 记忆。
SERVICE_NAME="run_jenkins_agent.service"
# enabel.此时会自动设置到特定目录的软链接。
sudo systemctl enable /home/kyo/github/linux_systemd_service/$SERVICE_NAME
# 立即启动服务
sudo systemctl start $SERVICE_NAME
# 查看服务状态
sudo systemctl status $SERVICE_NAME
# 慎用!!!重启电脑,验证下服务,是否真的可用
sudo reboot
# more...
sudo systemctl restart $SERVICE_NAME
sudo systemctl stop $SERVICE_NAME
sudo systemctl disable $SERVICE_NAME
- 关于 job 本身的 Build 配置。我的策略是,job 只调用某个特定的 python脚本。核心逻辑都在 python 脚本内完成。有很多考虑吧,主要还是考虑便于后续管理和本地测试。至于为什么用 python,没有用 nodejs 等其他脚本,倒是没有想太多,只是刚开始那段时间, 因为各种缘由,python用的较多;另外可能就是这种更新较慢或者历史较悠久的语言,总让人有一种 虚幻 的安全感吧。当然, python 各种强大的高质量的无可替代的三方库也是一个主要原因。我的配置仅供参考,唯一可以确定的是:这行代码和我在本机执行时,会产生一样的效果。这是我各种特殊的奇怪的设定,努力想实现的既定设计预期。仔细想来,在 python 和 nodejs 之间,我其实是很犹豫的。在另一个小需求里,我就采用了 nodejs 为主,混合调用 python 文件为辅的方式。单纯考虑语法, nodejs 还是更接近于其他现代语言一点,切换语言的心智成本,略低于直接切换到 Python。
bash /home/kyo/github/jenkins_python_shells/shell/main.sh card_state_backup --categorys=$categorys
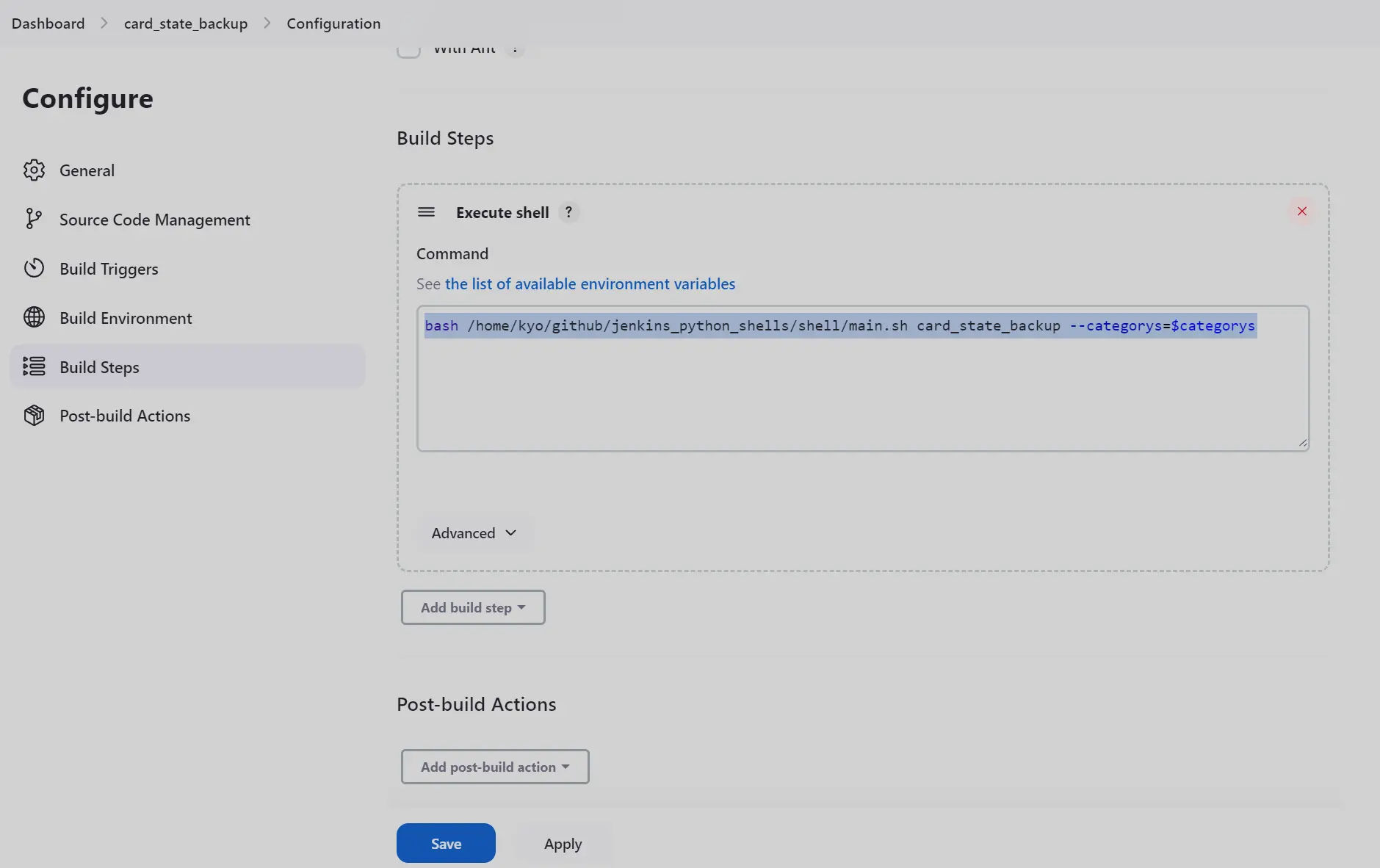
- 如果是有多个卡组,可能想要支持数组参数。jenkins原生没有直接的支持,我是配置为字符串,然后自己在脚本里基于 , split 为数组的。
- 记录一个最初遇到的 job 报错。那时候,还是用的内置 node,与既定目标文件,处于两个隔离的文件系统里。不过我当时并没有意识到。
02:38:22 with open(f"/home/kyo/github/card_state_backup/{category}_state.json", 'w') as f:
02:38:22 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
02:38:22 FileNotFoundError: [Errno 2] No such file or directory: '/home/kyo/github/card_state_backup/pimsleur_state.json'
02:38:22 Build step 'Execute shell' marked build as failure
02:38:23 Finished: FAILURE
- 另一个因为 user 问题,引起的 job 执行时特有的错误:
03:21:44 proc.wait(stderr=stderr_text)
03:21:44 File "/home/kyo/github/jenkins_python_shells/.venv/lib/python3.10/site-packages/git/cmd.py", line 657, in wait
03:21:44 raise GitCommandError(remove_password_if_present(self.args), status, errstr)
03:21:44 git.exc.GitCommandError: Cmd('git') failed due to: exit code(128)
03:21:44 cmdline: git push --porcelain -- origin
03:21:44 stderr: 'fatal: detected dubious ownership in repository at '/home/kyo/github/card_state_backup''
03:21:44 Build step 'Execute shell' marked build as failure
- service 安装与启动效果图:


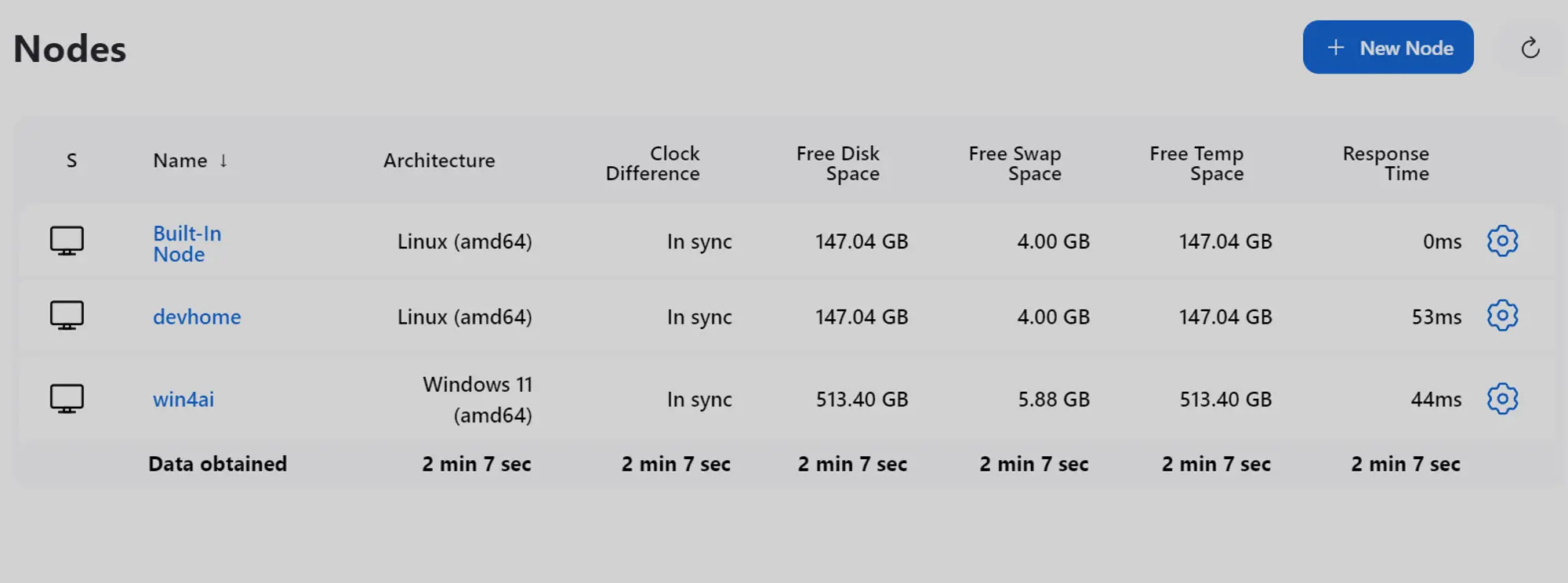
- Jenkins Node 配置完成后的效果图:
脚本内:获取卡片最新状态文件
- 这块逻辑高度个性化,没有一致的方法。
- 目前,我的卡组状态,是存储到本地搭建的 minIO 对象存储服务器里。从用户视角看,比较直观,就像一个文件资源管理器一样,也有点像网盘,不限速的那种哈哈哈。。。
- 我曾考虑把 文件服务器 整体上传备份,但是后来了解到 github 是有文件大小限制的。所以,此方案作罢。
- 关于卡组状态文件的获取,目前实际的做法是:基于 fastapi 写的 restapi 从 minIO 上读取的最新的状态文件。但是应该会继续这样做,因为 minIO 直接提供的 API 需要一些额外的配置,在每个地方都处理这些细节,会有一些不必要的对 minIO 的过度依赖。是的,我后续可能考虑直接或部分去除对 minIO 的依赖了。
脚本内:状态文件写入本地Git目录
for category in categorys:
json_data = self.fetchStateFromOnline(category=category)
state_file = f"{self.fetchCardRepoFolder()}{category}_state.json"
is_action_success = self.writeStateToLocal(
category=category, json_data=json_data)
action_result[category] = is_action_success
if is_action_success:
self.stateGitRepo.index.add(state_file)
# git commit: 只在确实有变化时,尝试commit
if self.stateGitRepo.is_dirty():
commit_date = datetime.today().strftime('%Y-%m-%d')
self.stateGitRepo.index.commit(f"add: update state {commit_date}")
- 主要是基于 GitPython 这个库来进行 Git 操作。这要比直接调用 git 命令,方便一些。
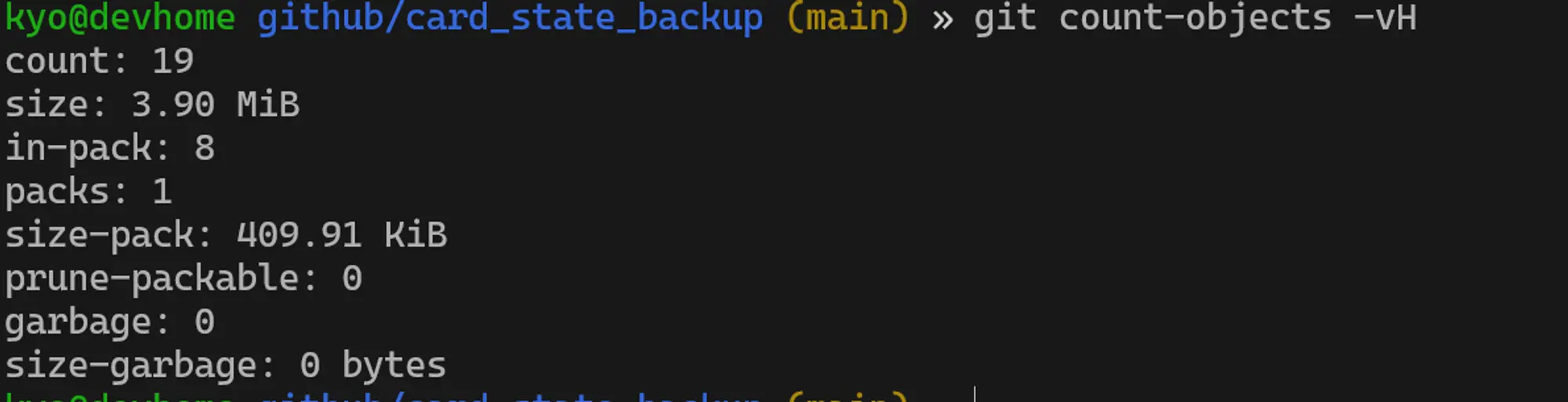
- 每个卡组的状态文件,最多只存储一个,即:卡组的状态文件的文件名,不会额外带上时间戳等日期信息。这样主要也是顾忌 github 的文件大小的限制。使用同名文件,这样每次提交,都属于增量变化,实际的文件体积的变化,就非常小了。
- 实际提交几次后,git 仓库的体积,确实没有成倍暴增,一直都是两个文件左右的大小:
git count-objects -vH
- 有个重要的细节,只在 git 状态为 dirty 时,才进行 commit。否则,可能会产生一个没有任何实际内容的空commit。
脚本内:本地Git目录提交到 Github
origin = self.stateGitRepo.remotes.origin
origin.push().raise_if_error()
这个倒没啥特殊的。刚开始查找相关 API 时,花费了点时间。
脚本内:发送邮件,告知执行结果
- 我是写了一个邮件发送的 restapi,供统一使用。此处其实是基于这个 API 的。
- 如果你是从零开始配置邮件服务,我认为直接使用第三方邮件服务可能会更好些。我目前使用的是 fastmail 的 Standard版本。但是实际使用下来,Basic 足够满足我的需要了。我目前主要使用的是 MaskMail 服务,可以使用邮箱替身来注册不同的网站。这样就不用担心某个网站泄露自己的邮件,导致最后不得不换邮箱的尴尬了。隐私敏感的人,强烈推荐试用。
- 发送邮件主要需要 subject 和 message 两个内容。我分享我这次写的一个简单的转换函数吧。主要是把前几步的执行结果,转换为更直观更易于我阅读的内容,方便我快速判定是否需要介入处理。
def converStrategyToMailPayload(self, info):
message = "明细:"
total = len(info)
success_item = 0
for key in info:
if info[key] == True:
success_item += 1
message += f"\n\t{key}: ✅"
else:
message += f"\n\t{key}: ❌"
subject = f"每日卡片状态同步:"
if total == success_item:
subject += "全部成功"
else:
subject += "部分失败!紧急!"
payload = {
"subject": subject,
"message": message
}
return payload
小感:比起 AI,我更喜欢 自动化
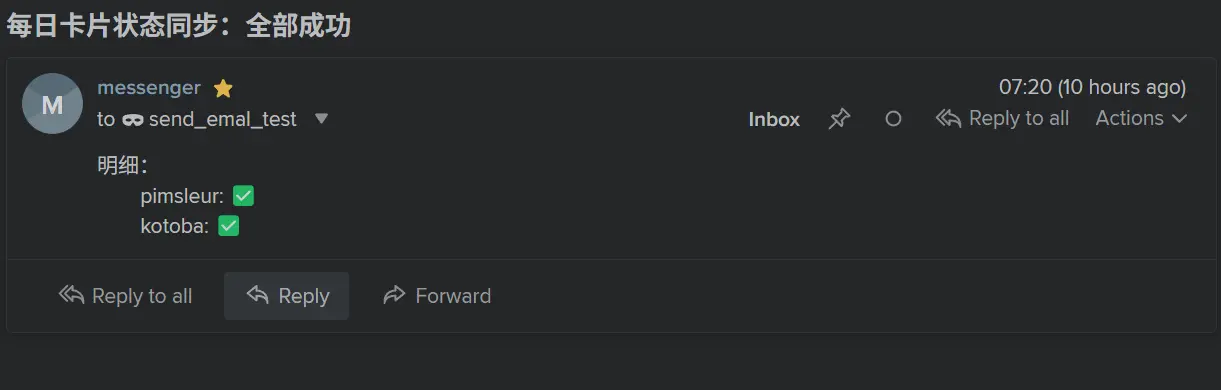
上图是早上收到的邮件。这个系统已经正式运行,并成为我日常生活的一部分了。
我不太确定未来 AI 究竟那发展到什么程度。但是,基于目前已知的表现,我并不看好。基于 概率 的产出,几乎很难在复杂的场景中发挥作用。真正和 概率 有某种关联,和人的 主观 更接近的工作,缺的到底是产出的数量,还是质量?比如 “电影” 吧。即使 AI 能基于文字生成视频进而生成电影,又能怎么样呢?我们现在,缺少的是电影,还是缺少高水准的电影?再多点烂片,又真的能颠覆电影行业吗?
我也去看了下最近大火的那个 音乐 生成的软件。毫不讳言,一个又一个的重金属垃圾品而已。
基于此,我认为 AI 最先淘汰的,反倒是哪些最会拍烂片的导演。又或者,只会堆砌词汇的烂音乐制作人。
这是一个奇怪的悖论。通常来说,一个新技术,更应该首先在更理性更客观的领域取得足够的成功。因为这些领域,标准相对确定。而人的 主观,则受各种不同因素的影响。但是现在 AI 似乎反过来了。
我在书上看到了不少历史上的技术泡沫或妄想,AI这次的狂欢,会不会也是另一场虚幻的泡影呢?
不论如何,我该如何自处呢?保持关注,是最基本的。保持批判性的态度,是必须的。把注意力集中到自己需要切实处理的问题上,然后借助各种成熟技术,争取实现 自动化, 进而尽可能降低二次处置的边际成本,才是我眼下最应该实际做的。
如果 AI 只是一场泡沫,那何时会破灭呢?我没法给出一个准确的时间点。但是基于大众情绪通常的规律,一旦 AI 无法持续满足大众的期待,大众热情褪去的速度,将是数倍于热情高涨的猛烈程度。我现在唯一需要谨慎考虑的是:暂时最好不要投资各种 AI 概念股,避免过于剧烈的资产波动。