「速记」自己动手,从 0 开始制作 7731 张 JLPT 词组闪卡
为什么制作闪卡, 而不是直接用各种单词书记忆单词?
制作闪卡, 最终是为了基于 间隔复习 的原理, 来可靠地记忆, 提升记忆的熟练度和准确度.
在音频App相关短句的记忆上, 间隔复习 给予了我完全不敢想象的远超预期的结果. 随着记忆的熟练度的提升, 句感, 节奏, 活用程度, 都有了一个质的飞跃.
我现在有一种信念: 没有 间隔复习, 再有效果的 学习 也无法真正发挥作用.或者更直接点说: 不复习, 等于没有学; 不间隔复习, 等于没有复习.
显而易见, 常规的纸质版单词书, 最大的弊端就是: 无法高效地 间隔复习. 纵然可以通过以小组为单位, 自己用 Excel 来复习. 但是当数量来到 千 级别时, 更精细地复习, 方能尽可能提高复习的效率.
当然, 另一个原因就是: 现有的日语词汇闪卡, 和我预期的都有一定的差距. 或者说: 我对他们的质量不放心. 我没有太多时间浪费. 我做一件事, 就需要适当保证事情的效果, 能在一个合理的预期区间波动.
我预期的日语词汇卡组,长什么样?
-
发音, 要能正确反应日语的音变. 如: ここ 罗马音标是 koko, 但是真实的发音是 kogo.
-
声音, 要尽可能自然些, 不要有太明显的机器腔调.
-
要聚焦于发音的记忆. 作为汉语母语者, 需要充分发挥汉字可以自由阅读的优势, 只着重记忆发音即可. 我没有统计, 但是我遇到的常用汉字, 相当一部分都和汉语意思相同或者有一定关联.
-
相对全面. 覆盖 N5 ~ N1. 我没有心情去分批去学. 要搞, 就一次性把词汇问题搞完. 而且这些都还是基础词汇. 计算机的专业词汇, 还需要额外整理和学习.
-
某种形式的 电子化, 方便我二次开发. 因为我要导入我自己的 闪卡系统中. 我不太喜欢 Anki 的那个交互. 以前吐槽过.不再赘述.
效果预览:
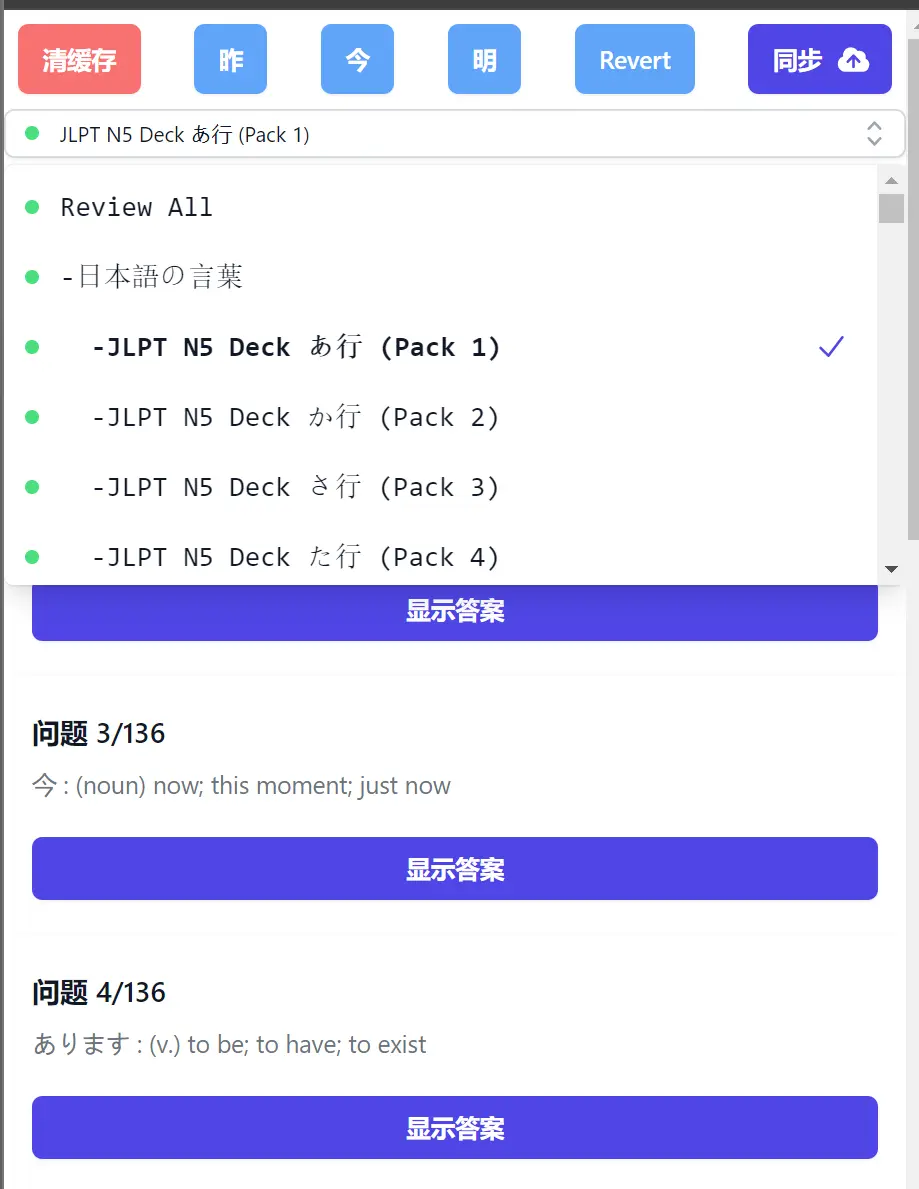
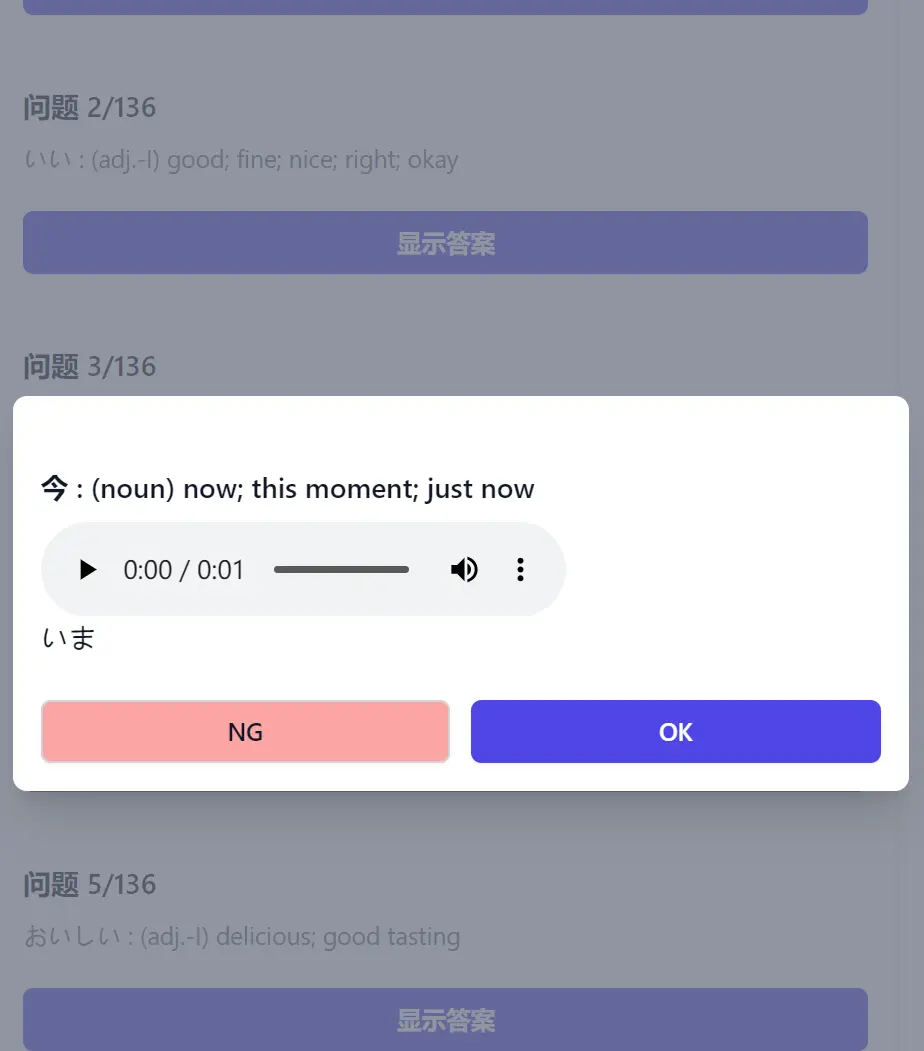
基本思路:
-
一.收集基础词汇信息: 基于网络资源, 整理出需要掌握的 N5 ~ N1 词汇.
-
二.音频制作: 基于 Google Translate的API,制作音频.
-
三.数据处理: 将数据格式调整为兼容我现有闪卡系统的格式.
-
四.闪卡系统改造: 支持多数据源.
一.收集词汇
可能的方式:
-
抓包 App 的网络请求.
-
Web浏览器 Devtool 抓包请求.
-
抓取页面 HTML, 手动解析.
数据源的选择:
尽量选择相对可靠的数据源.最好是自己体验过的, 较为熟悉的.否认来回返工, 就有点得不偿失了.
我的单词卡组制作, 参考了 fluentu.考虑到版权等问题, 不宜公开传播相应数据.所以, 我不打算具体进行技术层面的讨论, 也不会分享相关的数据.
二.音频制作
主要是基于 Google Translate 的半公开的 API.算是一个讨论较多的技术方案;但是 Google 并没有公开的开放 API. Google 也提供了 Text To Speech 的云服务,但是效果不行, 无法可靠地处理日语音变. 原因未知, 但是 Google Translate 生成的音频, 无论音质还是对音变的处理, 都是相当可靠和准确.
我分享一个简单的脚本. 实际用的时候, 肯定要适当改造下, 改为批量请求:
curl -o ./audio/ここに.mp3 https://translate.google.com/translate_tts?ie=UTF-8&client=tw-ob&tl=ja&q=%E3%81%93%E3%81%93%E3%81%AB
尝试修复: 短音频网页上, 可能无法播放.
音频过短时, 部分播放器和浏览器, 可能无法成功播放该音频.所以, 我在原始的音频上, 又追加了一个简单的 空白段. 我以前就用过这个策略, 这次更进一步, 简单封装为了一个 python 脚本:
from pydub import AudioSegment
from pydub.playback import play
import sys
# 原因: 太短的音频, 播放时会有截断.所有音频前|后需要各添加一定时长的 静音.
# 需要安装音频扩展
# apt-get install ffmpeg
def fixMp3File(rawMp3File, fixedMp3file):
# 加载你的音频文件
audio = AudioSegment.from_file(rawMp3File, format="mp3")
# 创建一个长度为500毫秒的静音
silence = AudioSegment.silent(duration=500) # duration in milliseconds
# 在音频前添加静音
audio = silence + audio
# 保存新的音频文件
audio.export(fixedMp3file, format="mp3")
if __name__ == "__main__":
rawMp3File = sys.argv[1]
fixedMp3file = sys.argv[2]
fixMp3File(rawMp3File, fixedMp3file)
这里为什么选择用 python 呢? 主要是 pydub 这个库, 用着实在是太方便了!!!
三.数据处理为统一的格式.
这一步, 个性化就很强了. 取决于你正在使用的闪卡系统.
我贴一个 Card 级别的数据结构吧:
{
"cardId": "3a194b1a7faed27465349ab1ff73d97464d41db818eb67571e2e472fff163388",
"content": {
"questionCue": "今 : (noun) now; this moment; just now",
"questionMedia": "",
"answerCue": "今 : (noun) now; this moment; just now",
"answerTransliteration": "いま",
"answerMedia": "./日本語の言葉/media/今.mp3"
},
"lastStudy": null,
"stage": null
}
可以很明显地看出来, 我在最初设计卡组的数据结构时, 就尽量去除了 卡组自身的一些特性, 尽量让数据结构具有通性. 这样后续添加新卡组时, 只需要将数据统一处理为这种格式即可, 后续的业务逻辑, 几乎不用修改.
另外就是, 汉字,发音等完全一致的, 就判定为同一个词汇, 在制作卡片时就直接过滤掉了.
.forEach(card => {
const { cardId } = card;
if (!wordState.card[cardId]) { // 大约有200个完全重复的词汇.此处会直接去除.
wordState.card[cardId] = card;
deck.cards.push(cardId);
}
})
四.闪卡系统改造
主要是要提供对多闪卡数据源的支持.当初, 只是作为一个快速使用的Demo, 没有太多考虑各种衍生需求.
虽然这个略显简陋的闪卡系统, 给我提供了巨大的帮助, 但是我还是不想花费太大精力.
这次依然本着能凑合就凑合着先用的想法, 用了一个简易的方案, 来区分不同的数据源.主要涉及以下修改
1.不同的网络路径, 对应不同的闪卡集合.
let stateCategory = window.location.pathname.replace(/\//g,'');
目前已经支持的卡组:
- /pismer: 音频App相关短句.
- /kotoba: 日语JLPT词组.
2.基于分类,切换使用不同的数据源.
import pimsleurState from '../../assets/data/pimsleur_state.json'
import kotobaState from '../../assets/data/kotoba_state.json'
const defaultStateCategory = "pimsleur";
const supportStateCategory = {
"pimsleur": pimsleurState,
"kotoba": kotobaState
};
// ref: https://stackoverflow.com/a/68001349
let stateCategory = window.location.pathname.replace(/\//g, '');
if (!supportStateCategory[stateCategory]) {
stateCategory = defaultStateCategory
}
const baseState = supportStateCategory[stateCategory];
- 本地存储前先压缩, 以解决 Storage exceeded the quota
这次日语单词的卡组, 体积有点太大.导致无法调用 localStorage 来存储.直接调用会报错.上限大小应该是 10M 左右.
chunk-GZ55BCQ2.js?v=0b51cb47:3750 Uncaught DOMException: Failed to execute 'setItem' on 'Storage': Setting the value of 'state_cards_kotoba' exceeded the quota
查看 localStorage 的大小, 可以在 devtools 控制台里执行以下 JS 代码:
var _lsTotal=0,_xLen,_x;for(_x in localStorage){ if(!localStorage.hasOwnProperty(_x)){continue;} _xLen= ((localStorage[_x].length + _x.length)* 2);_lsTotal+=_xLen; console.log(_x.substr(0,50)+" = "+ (_xLen/1024).toFixed(2)+" KB")};console.log("Total = " + (_lsTotal / 1024).toFixed(2) + " KB");
我刚开始想用 IndexedDB, 因为 Youtube 的浏览器上的视频下载就是存储到 IndexedDB 里的.但是, 总觉得有点繁杂.
还是用了个短平快的方案, 直接把字符串先压缩以下, 体积大约缩小到 12% 左右, 就可以正常存储了.改造后的 localCacheCardState 方法如下:
function localCacheCardState(cardState) {
// 必须提前将 cardState 转为字符串.
// 因为 cardState 有可能是一个 proxy 出来的对象.详见 Redux State相关材料.
const stateString = JSON.stringify(cardState);
// 需要异步延迟缓存.
// compress 方法,大约要耗时在300ms左右; 不异步,会导致切换卡组时,有卡顿感.
setTimeout(() => {
const compressedStr = LZString.compress(stateString);
localStorage.setItem(cacheKey, compressedStr);
}, 100);
}
主要用到是 LZString 库. 它的主页还有一个快速体验的 Demo.
压缩后的效果, 还是挺惊人的.不过时间消耗在 300ms 左右, 会卡UI,所以延迟在后台调用.当然,所谓的 后台 其实是后一个 eventloop 里.

小感: 确立方案时, 多做加法; 实施阶段, 多做减法
在怎样制作 JLPT 卡片, 其实我有很多脑洞想法, 比如: 用 ChatGPT 给中日含义相近的汉字自动打分等. 有些想法, 最终被实践了下来; 有些想法, 则被快速摒弃.
我有现实的时间压力. JLPT 是 7月份举行, 我必须尽可能快的开始词汇记忆问题.所以我时间的编码时间, 只有2天左右.
所以, 我必须搞清楚,到底最核心的地方在什么地方. 核心的地方, 需要分配更多的地方. 不是很重要的地方, 暂时先凑合着.
显而易见, 数据集的汉字和声音, 是核心的.即: 数据的收集是最核心的. 至于如何呈现, 其实我考虑过最坏的打算: 把 短句卡组的 代码copy一份, 直接修改让 词汇卡组用. 不过原来设计短句卡组时, 适当剥离了 数据和UI. UI真正用的是我们常用的 ViewModel, 这就导致我可以较快地让 短句卡组系统 较容易地支持 词汇卡组.
实施阶段, 必须要多做减法. 先把业务跑通. 因为在业务跑通前, 你是无法预知究竟哪个环节会是真正的时间或者技术瓶颈. 而自己那些天马行空的想法, 往往针对的是已知的可能的瓶颈.
简言之:
-
做之前, 多考虑不同的方案和策略, 争取为已知的问题, 寻找更优的解决方案.
-
具体实施的过车中, 尽量做减法, 非必要的优化先缓缓. 争取尽快先把业务能整体跑起来, 确认没有某些未知的 技术瓶颈.
关于 ChatGPT 的使用. 这次没有用 ChatGPT 来动态评定 日语词汇的频率和难度等信息,主要是因为 ChatGPT 的输出不稳定. 如果是少量词汇, 我可以手动校对; 但是对于 8000 多个词汇, 我可能没有太多时间和能力去校对.毕竟许多词汇, 我并不认识. 所以这个时候, 是用 ChatGPT 动态重新给词汇定级, 还是延用已有的 JLPT 分级方案, 显然后者更稳妥些.