如何用 robots.txt 验证工具,进一步排查无法手动往Google提交网页链接的问题?
我以后得适当克制下自己的碎碎念. 同时一篇文章, 尽量聚焦在一个适当的主题.不然自己以后查阅时,也很费劲.
问题:
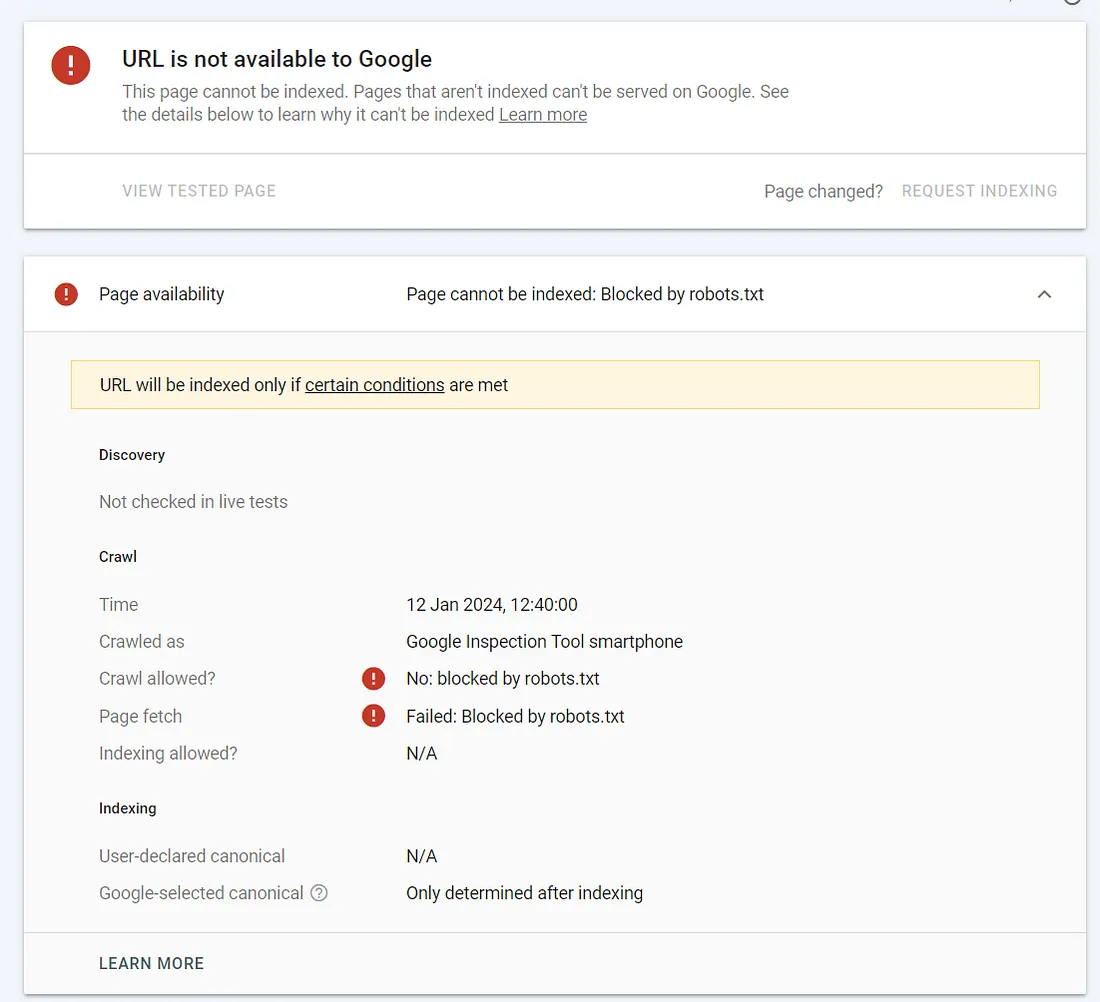
我昨天手动往 Google 提交索引时, 我发现总是提示 Crawl allowed? No: blocked by robots.txt. 这让我很困惑, 同时也直接导致我无法直接往 Google 提交自己的新博客链接.问题本身, 我已经解决了.但是进一步定位问题本身的方法,我认为有必要单独梳理下, 供后续参考.
问题本身很特殊.首先是 Google 没有更进一步的提示.然后就是 robots.txt 本身,初看上去,也没有明显会屏蔽 Google Robot的规则.还有就是: Google 已经收录了我一些页面,说明本身 Google 的爬虫肯定是能访问我的网站的.

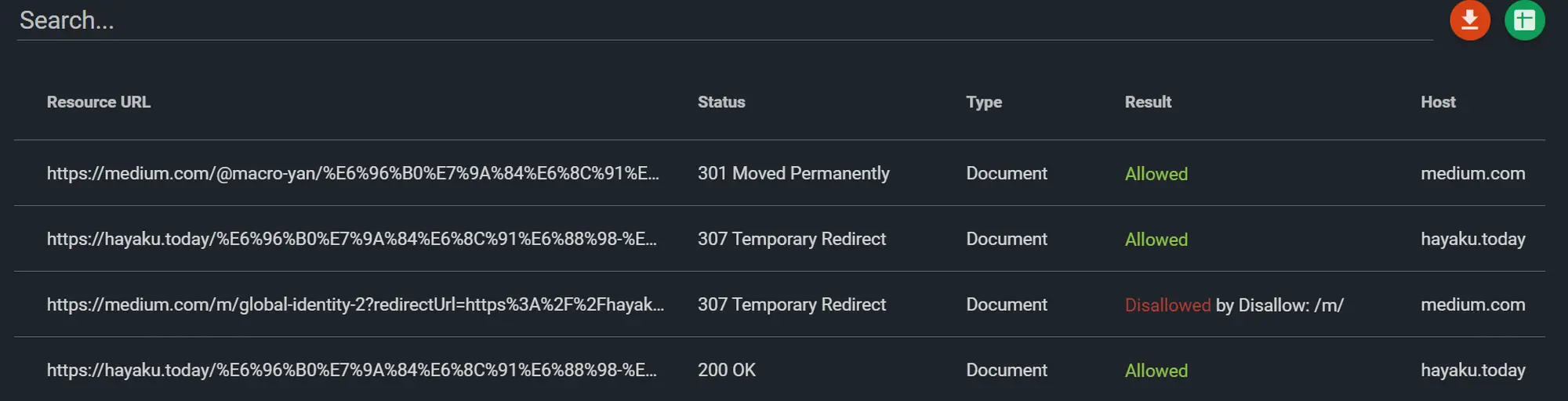
找到了一个 robots.txt 的验证网站.在勾选上 Check Resources 就能看到更进一步的问题:
原因:
我大致归纳下这件事发生的原因:
-
首先, 我当时的 博客是部署在 Medium 平台的.使用了自定义域名.
- 从robots视角, Medium 实现自定义域名的方式是:
- 访问目标网页, 完整页面地址为 $target_url.
- 307跳转到: https://medium.com/m/global-identity-2?redirectUrl=$target_url
- 再次307跳转到: $target_url?gi=c6125e5b62da (其中的 c6125e5b62da 每次都均不相同.作用未知.)
- Medium 提供的 robots.txt 中有一条规则:
User-Agent: * Disallow: /m/
如此. 就导致: 第一次307时, robot就无法继续爬取了.
解决方法:
基于原因, 可能的解决办法:
-
放弃使用手动往Google提交链接的功能. ==> 不可行. 原因是: Medium 生成的 sitemap 不全;每个页面关联的文章又有点随机, 这会导致部分文章,一直无法被 Google 爬虫感知到.
-
放弃使用自定义域名. 因为Meidum本身提供的二级子域名是没有这个问题的. ==> 不可行. 我想保留自己的域名.不指望赚钱,但是想保留自己的域名.
-
修改Medium提供的 robots.txt. ==> 不可行. Medium没有提供类似的功能. 我也设想过在网站单独部署一个 Nginx代理,单独处理 robots.txt. 但是略微有点复杂,而且担心会影响 Google 的爬虫爬取的效率.以前就发生过 Google 判定服务器性能低,延缓进一步爬取内容的问题.
-
最后只剩下一个选项: 换用自定义功能的其他平台. ==> 可行.最终也是这么做的.需要注意的是,新平台必须支持自定义博客链接,不然已经被Google收录的博文链接,就会失效了.
效果:
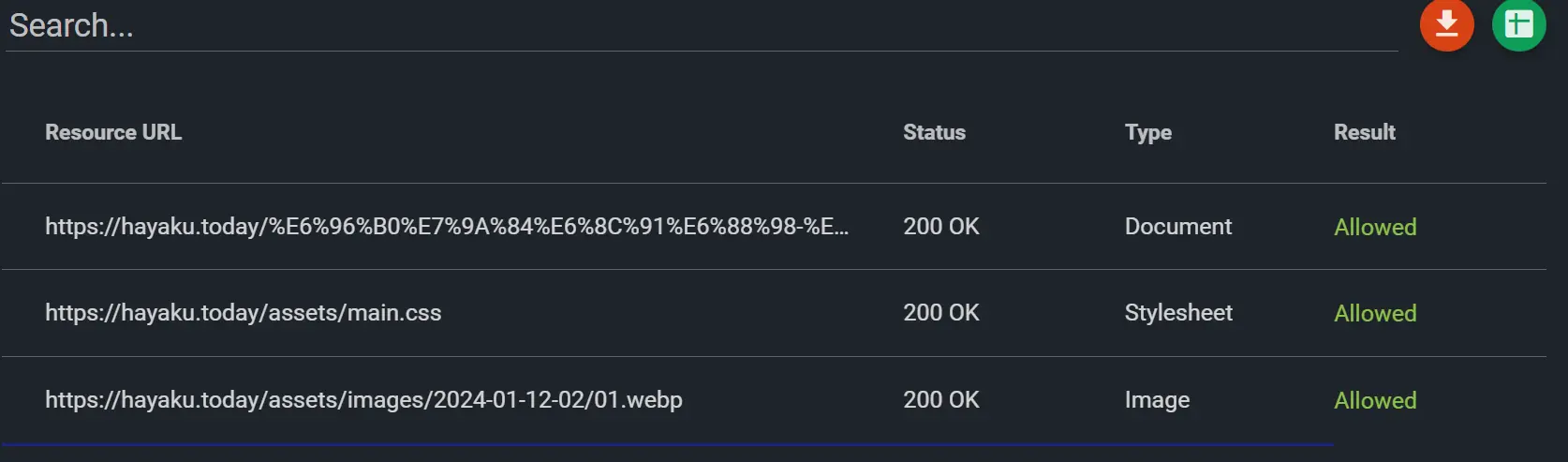
我最终是换到了 github pages.使用的是平台默认的 jekyll, 支持自定义每篇博客文章的链接. 效果非常好:
-
robots.txt 的校验, 现在能通过了:
-
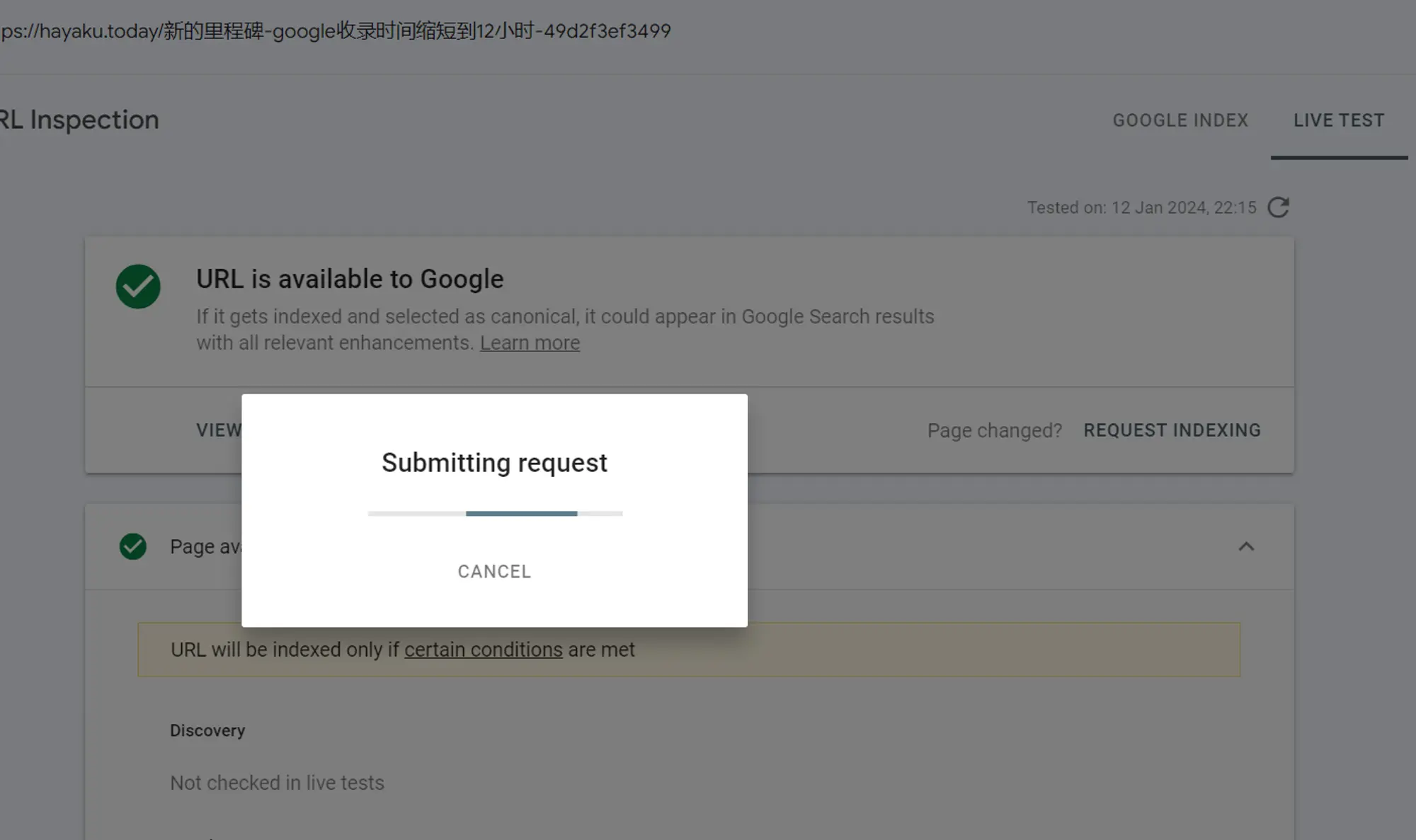
可以手动往 Google 提交域名了.而且我发现我手动提交的,几乎会被立即收录到Google索引里.这说明收录慢,确实不是我的博文质量的问题,就是 Medium 的各种不友好设置,导致我的文章被爬虫漏掉了.
-
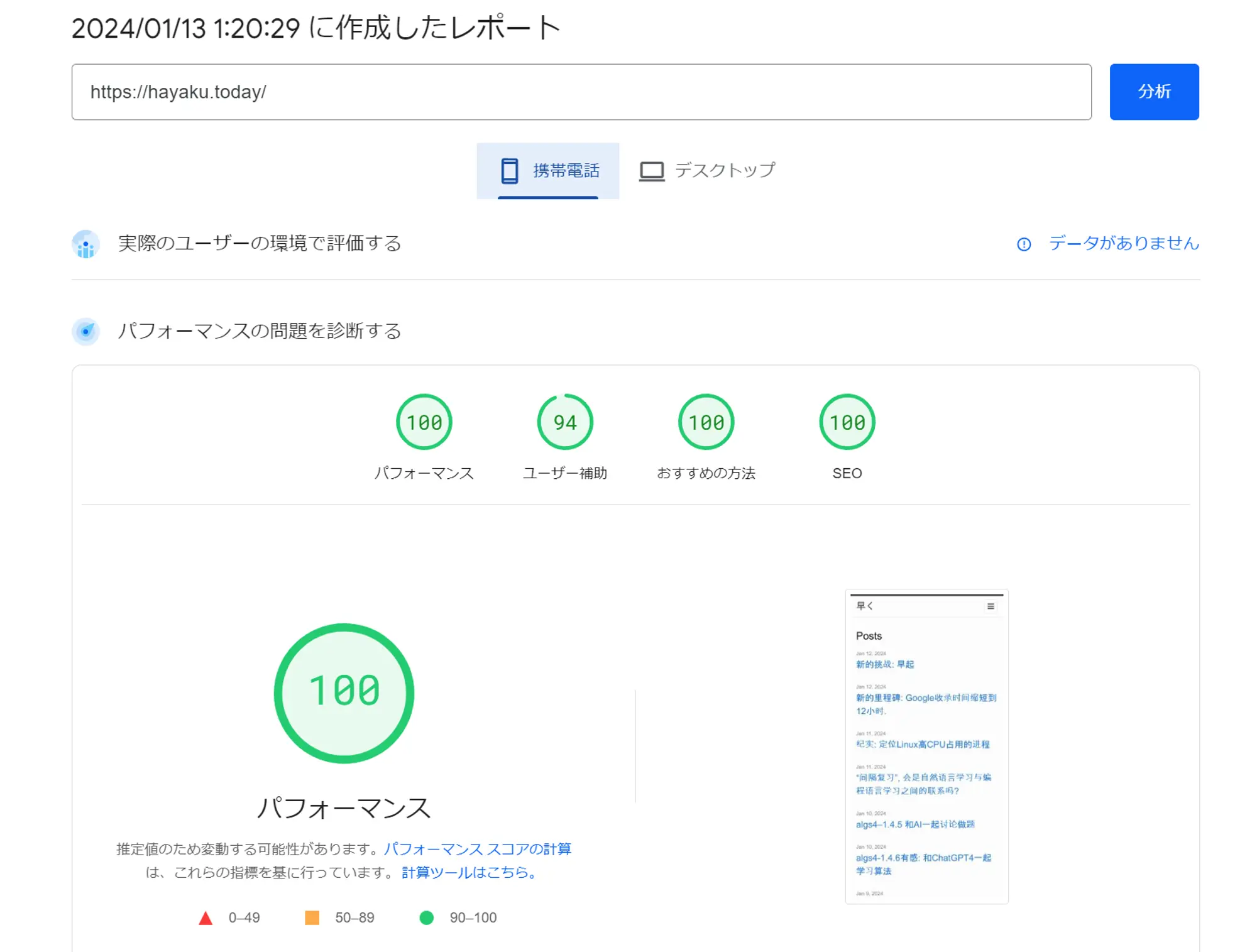
PageSpeed Insights 网站访问速度评分,现在是满分!
小感:
每一份”便利”, 都是明码标价的.经常用的东西, 还是要稳定性第一,在此基础上, 自定义程度越高, 应该就能用得越长久.